Bio/statistics handout 14: More about Markov matrices
The notion of a Markov matrix was introduced in the previous handout, this being an N ´ N matrix A that obeys the following conditions:
∑ Ajk ≥ 0 for all j and k.
∑ A1k + A2k + ··· + ANk = 1 for all k.
(14.1)
These two conditions are sufficient (and also necessary) for
the interpretation of the components of A as
conditional probabilities. To this end,
imagine a system with N possible states, labeled by the integers starting at
1. Then Ajk
can represent the conditional probability that the system is in state j at time
t if it is in state k at time t-1. In
particular, one sees Markov matrices arising in a dynamical system where the
probabilities for the various states of the system at any given time are
represented by an N-component
vector, ![]() (t), that evolves in time according to the formula
(t), that evolves in time according to the formula
![]() (t) = A
(t) = A![]() (t-1) .
(t-1) .
(14.2)
A question that is often raised in
this context is whether the system has an equilibrium probability function,
thus some non-zero vector ![]() *, with non-negative entries that sum to 1, and that obeys A
*, with non-negative entries that sum to 1, and that obeys A![]() * =
* = ![]() *. If so, there is
the associated question of whether the t ® ∞ limit of
*. If so, there is
the associated question of whether the t ® ∞ limit of ![]() (t) must necessarily converge to the equilibrium
(t) must necessarily converge to the equilibrium ![]() *.
*.
There
are three points to make that allow us to answer these questions.
∑
The matrix
A always has an eigenvector with eigenvalue 1.
∑
In the case that each entry of A is strictly
positive, then every non-zero vector in the kernel of A – I has either all positive entries or all
negative entries.
∑
In the case that each entry of A is strictly
positive, there is a vector in the kernel of A – I whose entries are positive and sum to 1.
∑
In the case that each entry of A is strictly
positive, the kernel of A – I is
one dimensional. Furthermore, there is
unique vector in the kernel of A – I whose
entries are positive and sum to 1.
∑
In the case that each entry of A is strictly
positive, all other eigenvalues have absolute value strictly less than 1.
(14.3)
I will elaborate on these points in Section b, below.
a) Solving Equation (14.2)
In the case that A has a basis of
eigenvectors, then (14.2) can be solved by writing matters using the basis of
eigenvectors. To make this explicit, I
denote this basis of eigenvectors as {![]() 1, …,
1, …, ![]() n} and I use lk
to denote the eigenvector of
n} and I use lk
to denote the eigenvector of ![]() k. Here, my
convention has l1 = 1 and I
take
k. Here, my
convention has l1 = 1 and I
take ![]() 1 to be the eigenvector with eigenvalue
1 whose entries sum to 1. As I explain
below, the entries of any k > 1 version of
1 to be the eigenvector with eigenvalue
1 whose entries sum to 1. As I explain
below, the entries of any k > 1 version of ![]() k must sum to zero. Granted this, then
k must sum to zero. Granted this, then ![]() (0) must have the expansion
(0) must have the expansion
![]() (0) =
(0) = ![]() 1 + ∑2≤k≤n ck
1 + ∑2≤k≤n ck
![]() k .
k .
(14.4)
With regards to the coefficient 1
in front of ![]() 1, this is a consequence of our requirement that
the entries of
1, this is a consequence of our requirement that
the entries of ![]() (0) sum to one.
Indeed, as the entries of each k > 1 version of
(0) sum to one.
Indeed, as the entries of each k > 1 version of ![]() k sum to zero and those of
k sum to zero and those of ![]() 1 sum to 1, then the sum of the entries of
1 sum to 1, then the sum of the entries of ![]() (0) is what ever we put as coefficient in front of the
(0) is what ever we put as coefficient in front of the ![]() 1term.
1term.
By
way of an example, consider the 2 ´ 2 case where
A = ![]() .
.
(14.5)
The eigenvalues
in this case are 1 and -![]() and the associated eigenvectors
and the associated eigenvectors ![]() 1 and
1 and ![]() 2 in this case can be taken to be
2 in this case can be taken to be
![]() 1 =
1 = ![]() and
and ![]() 2 =
2 = ![]() .
.
(14.6)
For this 2 ´ 2
example, the most general form for ![]() (0) is
(0) is
![]() (0) =
(0) = ![]() ,
,
(14.7)
where c2 can be any number that obeys -![]() ≤ c2 ≤
≤ c2 ≤ ![]() .
.
Returning
to the general case, it then follows from (14.2) and (14.4) that
![]() (t) =
(t) = ![]() 1 + ∑1≤k≤n cl
lt
1 + ∑1≤k≤n cl
lt ![]() k.
k.
(14.5)
Thus, as t ®
∞, we see that in the case where each entry of A is positive, the limit
is
limt®0 ![]() (0) =
(0) = ![]() 1 .
1 .
(14.6)
Note
that in our 2 ´ 2 example,
![]() (t) =
(t) = ![]() ,
,
(14.7)
b) Proving things
about Markov matrices.
My goal here is to convince you that a Markov matrix obeys
the points in (14.3).
Point 1: As noted, an
equilibrium vector for A is a vector, ![]() , that obeys A
, that obeys A![]() =
= ![]() . Thus, it is an
eigenvector of A with eigenvalue 1. Of course, we have also imposed other
conditions, such as its entries must be non-negative and they should sum to
1. Even so, the first item to note is
that A does have an eigenvector with eigenvalue
1. To see why, observe that the vector
. Thus, it is an
eigenvector of A with eigenvalue 1. Of course, we have also imposed other
conditions, such as its entries must be non-negative and they should sum to
1. Even so, the first item to note is
that A does have an eigenvector with eigenvalue
1. To see why, observe that the vector ![]() with entries all equal
to 1 obeys
with entries all equal
to 1 obeys
AT![]() =
= ![]()
(14.8)
by virtue of the second condition in (14.1). Indeed, if k is any given integer, then the k’th entry of AT![]() is A1k + A2k + ··· + ANk and this sum is assumed to be equal to 1,
which is the k’th entry of
is A1k + A2k + ··· + ANk and this sum is assumed to be equal to 1,
which is the k’th entry of ![]() .
.
This
point about AT is relevant since det(AT - lI) = det(A - lI) for any real number l. Because AT – I is not invertible, det(AT
- I) is zero. Thus, det(A - I) is also zero and
so A – I is not invertible. Thus it has
a positive dimensional kernel. Any
non-zero vector in this kernel is an eigenvector for A with eigenvalue
1.
Point 2: I assume for this point that all of A’s entries are
positive. Thus, all Ajk
obey the condition Ajk > 0. I have to demonstrate to you that there is no
vector in the kernel of A - I with whose entries are not all positive or all
negative. To do this, I will assume that
I have a vector that violates this conclusion and demonstrate why this last
assumption is untenable. To see how this
is going to work, suppose first that only the first entry of ![]() is zero or negative
and the rest are non-negative with at least one positive. Since
is zero or negative
and the rest are non-negative with at least one positive. Since ![]() is an eigenvector of A
with eigenvalue 1,
is an eigenvector of A
with eigenvalue 1,
v1 = A11 v1 + A12
v2 + ··· + A1nvn .
(14.9)
Now, A11 is positive,
but it is less than 1 since it plus A21 + A31 + ··· + An1
give 1 and each of A21, …, An1
is positive. As a consequence, (14.9)
implies that
(1 – A11) v1 = A12 v2
+ ··· + A1n vn
(14.10)
To continue, note that the left
hand side of this equation is negative if v1 < 0 and zero if v1
is equal to zero. Meanwhile, the right
hand side to this last equation is strictly positive. Indeed, at least one
k > 1 version of vk is positive and its
attending A1k is positive, while no k > 1 versions of vk are negative nor are any Ajk. Thus, (14.10) equates a negative or zero left
hand side with a positive right hand side and this is nonsense. In this way, I see that I could never have an
eigenvector of A with eigenvalue 1 that had one
negative or zero entry with the rest non-negative with one or more
positive.
Here
is the argument when two or more of the vk’s
are negative or zero and the rest are greater than or equal to zero with at
least one positive: Lets
suppose for simplicity of notation that v1 and v2 are
either zero or negative, and that rest of the vk’s
are either zero or positive. Suppose
also that at least one k ≥ 3 version of vk
is positive. Along with (14.9), we have
v2 = A21v1 + A22v2
+ A23v3 + ··· + A2nvn
(14.11)
Now add this equation to (14.9) to
obtain
v1 + v2 = (A11 + A21)
v1 + (A12 + A22) v2 + (A13
+ A23) v3 + ··· + (A1n + A2n) vn .
(14.12)
Now, according to (14.1), the sum
A11 + A21 is positive and strictly less than 1 since it
plus the strictly positive A31+ ··· + An1 is equal to
1. Likewise, A21 + A22
is strictly less than 1. Thus, when I write (14.12) as
(1 – A11- A21) v1 + (1 – A21
– A22) v2 = (A13 + A23) v3
+ ··· + (A1n + A2n) vn ,
(14.13)
I again have an expression where
the left hand side is negative or zero and where the right hand side is greater
than zero. Of course, such a thing can’t
arise, so I can conclude that the case with two negative versions of vk and one or more positive versions can not
arise.
The argument for the general case is very much like this last argument so I walk you through it in one of the exercises.
Point 3:
I know from Point 1 that there is at least one non-zero eigenvector of A
with eigenvalue 1.
I also know, this from Point 2, that either all
of its entries are negative or else all are positive. If all are negative, I can multiply it by –1
so as to obtain a new eigenvector of A with eigenvalue
1 that has all positive entries. Let r
denote the sum of the entries of the latter vector. If I now multiply this vector by ![]() , I get an eigenvector whose entries are all positive and sum
to 1.
, I get an eigenvector whose entries are all positive and sum
to 1.
Point 4:
To prove this point, let me assume, contrary to the assertion, that
there are two non-zero vectors in the kernel of A – I and one is not a multiple
of the other. Let me call them ![]() and
and ![]() . As just explained, I
can arrange that both have only positive entries and that their entries sum to
1, this by multiplying each by an appropriate real number. Now, if
. As just explained, I
can arrange that both have only positive entries and that their entries sum to
1, this by multiplying each by an appropriate real number. Now, if ![]() is not equal to
is not equal to ![]() , then some entry of one must differ from some entry of the
other. For the sake of argument, suppose
that v1 < u1.
Since the entries sum to 1, this then means that some other entry of
, then some entry of one must differ from some entry of the
other. For the sake of argument, suppose
that v1 < u1.
Since the entries sum to 1, this then means that some other entry of ![]() must be greater
than the corresponding entry of
must be greater
than the corresponding entry of ![]() . For the sake of
argument, suppose that v2 > u2. As a consequence the vector
. For the sake of
argument, suppose that v2 > u2. As a consequence the vector ![]() -
-![]() has negative first entry and positive second entry. It is also in the kernel of A – I. But, these conclusions are untenable since I
already know that every vector in the kernel of A – I has either all positive
entries or all negative ones. The only escape from this logical nightmare is to conclude that
has negative first entry and positive second entry. It is also in the kernel of A – I. But, these conclusions are untenable since I
already know that every vector in the kernel of A – I has either all positive
entries or all negative ones. The only escape from this logical nightmare is to conclude that ![]() and
and ![]() are equal.
are equal.
This then
demonstrates two things: First, there is
a unique vector in kernel(A – I) whose entries are
positive and sum to 1. Second, any one
vector in kernel(A – I) is a scalar multiple of any
other and so kernel(A – I) has dimension 1.
Point 5; Suppose here that l is an eigenvalue
of A and that l > 1 or that l ≤ -1. I need to demonstrate that this assumption is
untenable and I will do this by deriving some patent nonsense by taking it to
be true. Let me start by supposing only
that l is some eigenvector of A with out making the
assumption about its size. Let ![]() now represent some
non-zero vector in the kernel of A - lI. Thus, l
now represent some
non-zero vector in the kernel of A - lI. Thus, l![]() = A
= A![]() . Now, if I sum the
entries on both sides of this equation, I find that
. Now, if I sum the
entries on both sides of this equation, I find that
l (v1+
···+vn) =
(A11+ ··· +An1) v1 + (A12+
··· +An2) v2 + ··· + (A1n+ ··· +Ann)
vn
(14.14)
As a consequence of the second
point in (1.1), this then says that
l (v1+
··· +vn) = v1+ ··· +vn
(14.15)
Thus, either l = 1
or else the entries of ![]() sum to zero.
sum to zero.
Now
suppose that l > 1. In this
case, the argument that I used in the discussion above for Point 2 can be
reapplied with only minor modifications to produce the ridiculous conclusion
that something negative is equal to something positive. To see how this works, remark that the
conclusion that ![]() ’s entries sum to zero implies that
’s entries sum to zero implies that ![]() has at least one
negative entry and at least one positive one.
For example, suppose that the first entry of
has at least one
negative entry and at least one positive one.
For example, suppose that the first entry of ![]() is negative and the
rest are either zero or positive with at least one positive. Since
is negative and the
rest are either zero or positive with at least one positive. Since ![]() is an eigenvector with
eigenvalue l, we have
is an eigenvector with
eigenvalue l, we have
l v1
= A11v1 + A12v2 + ··· + A1nvn ,
(14.16)
and thus
(l - A11) v1 = A12 v2
+ ··· + A1nvn .
(14.17)
Note that this last equation is
the analog in the l > 1 case of (14.9).
Well since l > 1 and A11 < 1, the left hand side of
(14.17) is negative. Meanwhile, the
right hand side is positive since each A1k that appears here is
positive and since at least one k ≥ 2 version of vk
is positive.
Equation
(14.3) has its l > 1 analog too, this where the (1 – A11 – A21)
is replaced by (l - A11 – A21) and where (1 – A12
– A22) is replaced by (l - A12 – A22). The general case where ![]() has some m < n
negative entries and the rest zero or positive is ruled out by these same sorts
of arguments.
has some m < n
negative entries and the rest zero or positive is ruled out by these same sorts
of arguments.
Consider
now the case where l ≤ -1. I can
rule this out using the trick of introducing the matrix A2 =
A·A. This is done in three steps.
Step
1: If A obeys (14.1) then so does
A2. If all entries of A are
positive, then this is also the case for A2. To see all of this is true, note that the
first point holds since each entry of A2 is a sum of products of the
entries of A and each of the latter is positive. As for the second point in (14.1), note that
∑1≤m≤n (A2)mk = ∑1≤m≤n
(∑1≤j≤n AmjAjk)
(14.18)
Now switch the orders of summing
so as to make the right hand side read
∑1≤j≤n (∑1≤m≤n
Amj) Ajk .
(14.19)
The sum inside the parenthesis is 1 for each j because A obeys the second point in (14.1). Thus, the right hand side of (14.8) is equal to
∑1≤j≤n Ajk ,
(14.20)
and such a sum is equal to 1, again due to the second point in (1.1).
Step
2: Now, if ![]() is an eigenvector of A
with eigenvalue l,
then
is an eigenvector of A
with eigenvalue l,
then ![]() is an eigenvector of A2
with eigenvalue l2. In the case that l < -1, then l2 > 1.
Since A2 obeys (14.1) and all of its entries are positive, we
know from what has been said so far that it does not have eigenvalues that are greater than 1. Thus, A has no eigenvalues
that are less than –1.
is an eigenvector of A2
with eigenvalue l2. In the case that l < -1, then l2 > 1.
Since A2 obeys (14.1) and all of its entries are positive, we
know from what has been said so far that it does not have eigenvalues that are greater than 1. Thus, A has no eigenvalues
that are less than –1.
Step 3: To see that –1 is not an eigenvalue
for A, remember that if ![]() were an eigenvector
with this eigenvalue, then its entries would sum to
zero. But
were an eigenvector
with this eigenvalue, then its entries would sum to
zero. But ![]() would also be an
eigenvector of A2 with eigenvalue 1 and we
know that the entries of any such eigenvector must either be all positive or
all negative. Thus, A can’t have –1 as
an eigenvalue either.
would also be an
eigenvector of A2 with eigenvalue 1 and we
know that the entries of any such eigenvector must either be all positive or
all negative. Thus, A can’t have –1 as
an eigenvalue either.
Exercises:
1. The purpose of this exercise is to walk you through the argument for the second point in
(14.3). To start, assume that ![]() obeys A
obeys A![]() =
= ![]() and that the first k
< n entries of
and that the first k
< n entries of ![]() are are negative or zero and the rest eithe
zero or positive with at least one positive.
are are negative or zero and the rest eithe
zero or positive with at least one positive.
a) Add the
first k entries of the vector A![]() and write the resulting equation asserting that the latter
sum equal to that of the first k entries of
and write the resulting equation asserting that the latter
sum equal to that of the first k entries of ![]() . In the case k = 2,
this is (14.12).
. In the case k = 2,
this is (14.12).
b) Rewrite the
equation that you got from a) so that all terms that involve v1, v2,
…, and vk are on the left hand side and
all terms that involve vk+1, …, vn
are on the right hand side. In the case
k = 2, this is (14.13).
c) Explain why the
left hand side of the equation that you get in b) is negative or zero while the
right hand side is positive.
d) Explain why the results from c) forces you to
conclude that every eigenvector of A with eigenvalue
1 has entries that are either all positive or all negative.
2. a) Consider the matrix A = 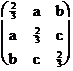 . Find all possible values for a, b and c that
. Find all possible values for a, b and c that
make this a Markov matrix.
b)
Find the eigenvector for A with eigenvalue
1 with positive entries that sum to 1.
c)
As a check on you work in a), prove that your values of a, b, c are such
that A
has eigenvalue ![]() . Find two linearly
independent eigenvectors for this eigenvalue.
. Find two linearly
independent eigenvectors for this eigenvalue.
3. This problem plays around with some of our
probability functions.
a) The exponential probability function is
defined on the half line [0, ∞).
The version with mean m is the
function x ® p(x) = ![]() e-x/m . The standard deviation is also m. If
R > 0, what is the probability that x ≥ (R+1)m?
e-x/m . The standard deviation is also m. If
R > 0, what is the probability that x ≥ (R+1)m?
b) Let Q(R) denote the function of R you just derived in a). We know apriori that Q(R) is no greater than 1/R2 and so R2Q(R) ≤ 1. What value of R maximizes the function R ® R2 Q(R) and give the value of R2 Q(R) to two decimal places at this maximum. You can use a calculator for this last part.
c) Let p(x) denote
the Gaussian function with mean zero and standard deviation s.
Thus, p(x) = ![]()
![]() . We saw that when R
≥ √2s, then the probability
that x is greater than Rs is less than
. We saw that when R
≥ √2s, then the probability
that x is greater than Rs is less than ![]() R
R![]() . Let Q(R) now denote
the function on the half line [√2 s,
∞) that sends R to
. Let Q(R) now denote
the function on the half line [√2 s,
∞) that sends R to ![]() R
R![]() . We know that Q(R)
≤ 1/R2.
. We know that Q(R)
≤ 1/R2.
What value of R makes R2Q(R) maximal? Use a calculator to write the value of R2Q(R) at its maximum to two decimal places.
d) Let L > 0 and let x ® p(x) denote the uniform probability function on the interval where
-![]() L ≤ x ≤
L ≤ x ≤ ![]() L. This probability
has mean 0 and standard deviation
L. This probability
has mean 0 and standard deviation ![]()
![]() L. Suppose that R is
larger than 1 but smaller than √3.
What is the probability that x has distance R
L. Suppose that R is
larger than 1 but smaller than √3.
What is the probability that x has distance R![]()
![]() L or more from the origin?
L or more from the origin?
e) Let R ®
Q(R) denote the function of R that gives the probability from d) that x has
distance at least R![]()
![]() L from the origin. We
know that R2Q(R) ≤ 1.
What value of R in the interval [1, √3] maximizes this function
and what is its value at its maximum?
L from the origin. We
know that R2Q(R) ≤ 1.
What value of R in the interval [1, √3] maximizes this function
and what is its value at its maximum?