Bio/statistics Handout 4: The statistical inverse problem
· Inverses in statistics: Here is a basic issue in statistic: You do an experiment some large number, say N, times and thus generate a sequence, {za}1≤a≤N of outcomes. In general, an experiment is done to test some hypothesis. This is to say that you have a model that is meant to predict the outcomes. The model might depend on some auxillary, ‘input’ parameters. It is convenient to label these input parameters by consecutive integers starting at 1 so that if there are n such parameters, then any choice for their values defines a vector, q º (q1, . . . , qn) in n-dimensional Euclidean space. The ultimate goal is to estimate the true value, qtr = (qtr1, . . ., qtrn) given the observed data, {za}.
A more realistic approach is to use the observed data to generate a probability function on the possible values for q. There are many ways to do this, each leading to a somewhat different probability function on the space of parameter values for our theory. I describe two. There are four steps in each, the first three shared by both.
Step 1: Both start by using the theoretical model, perhaps augmented with experimental input, to produce a function, ƒ(w|q), that gives the probability that the outcome of the experiment is w = (w1, . . . , wN) given that the input data is the point q. Any theory whose point is to predict outcomes from initial data will be able to produce such a function.
Step 2: Let us now suppose that the output of the experiment, the data z = {za}1≤a≤n, can take only a finite set of values. This is the usual case since data is only measured to some fixed decimal place. Let W denote the set of all possible output values. This step describes get a probability function on W that can be deduced from the experiments. This function is obtained in the following manner: Run the experiment many times. Now take the probability of any given w Î W to be the percentage of the experiments whose output z, is the given vector w. Use P(w) to denote the probability assigned to w.
Step 3: Introduce Q
to denote the possible values for the input parameters. I am assuming that this set is finite. Such is usually the case if for no other
reason then the fact that one can only measure the input parameters to some
fixed decimal place. Our theoretical
model (if it is any good at all) predicts the outcomes from the inputs. In particular, any theoretical model worthy
of the name will give us a function, f(w|q), whose value is the probability of finding
outcome w given that the input parameter is q.
·
The first probability function:
At this point, the two methods for generating a probability function on Q differ in a very fundamental way. To elaborate, note first that the theoretical
model predicts the outcome of an experiment given the values of the input
parameters, and so makes the predicted output value a random variable on the
space Q. Now turn this around, so as to reverse cause
and effect, and make the seemingly outrageous assumption that the parameter
values are random variables on the space of possible outputs. If such were the case, there would then be a
conditional probability, P(q|w), that gives the probability of the parameter value q given that the output is w. If we had such conditional probabilities,
then we could define a probability function, PQ, on Q using the
rule
PQ(q) º ∑wÎW P(q|w) P(w) .
(4.2)
The problem is that theories usually tell us the conditional probability of seeing the outcome given the input, not vice-versa.
Step 4: One way to circumvent this unfortunate state of affairs is to take a reasonable guess for what P(q|w) might look like. One particular guess takes
P*(q|w) º
![]() f(w|q) where Z(w) = ∑qÎQ f(w|q).
f(w|q) where Z(w) = ∑qÎQ f(w|q).
(4.3)
(Note that I divided by Z(w) so that the sum over all q of P*(q|w) is 1 as it should be for a conditional probability.)
Using this P*(q|w) for P(q|w) in (4.2) gives a guess at a reasonable probability function on Q:
P*(q) º
∑wÎW
![]() f(w|q) P(w) .
f(w|q) P(w) .
(4.4)
Rougly
speaking, the input parameters with the largest P* probability are the values for q that are predicted by the theoretical model to give the most
frequently observed outputs.
This method of reversing cause and effect is known as ‘Bayesian statistics’. It is quite popular now.
By the way,
computing P* in (4.4) can be
viewed as an exercise in matrix multiplication.
To see why, label the possible outcomes by consecutive integers starting
at 1, and likewise label the possible input parameters. Now, let xk
denote the value of P on the k’th output parameter,
and let yj denote the as yet unknown value
of P* on the j’th input parameter.
Let ajk denote the value of ![]() f(w|q)
when w is the k’th
output parameter and q is the j’th input parameter.
With this notation set, then (4.4) reads:
f(w|q)
when w is the k’th
output parameter and q is the j’th input parameter.
With this notation set, then (4.4) reads:
y1 = a11 x1 + a12 x2 + ··· ,
y2 = a21 x2 + a22 x2 + ··· ,
··· etc. ···
(4.5)
· The second probability function. This second method works only in certain circumstances—when a certain matrix is invertible. However, it has the advantage of not reversing cause and effect.
Step 4: We can look for a probability function, Q(q), on Q that produces the probability function P(w)
using the formula
P(w) = ∑qÎQ f(w|q) Q(q) for all w Î W.
(4.6)
The goal then is to solve the preceding equation for the values of Q. This is to say that one must invert the ‘matrix’ whose coefficients are f(w|q).
To make the connection to linear algebra explicit, label the possible values for the input parameter, the elements of Q, consecutively from 1 by integers. Likewise, label the possible output values, thus the points in W. This done, let xk again denote the value of P on the k’th output parameter, and let yj again denote the as yet unknown value of Q on the j’th input parameter. Let bkj denote the value of f(w|q) when w is the k’th output and q the j’th input. The preceding equation then reads
x1 = b11y1 + b12y2 + ···
x2 = b21y1 + b22y2 + ···
··· etc. ···
(4.7)
Thus, to find the values for {yk}, our task is to invert the matrix B whose coefficients are the numbers {bkj} just defined. Note that this task is hopeless if B is not a square matrix or, when square, it is not invertible. However, in the latter cases, there are other approaches to take, some of which are discussed later in the course.
·
An example: To see how this
might work with some numbers, suppose that the space W has three elements with
probabilities labeled x1 = ![]() , x2 =
, x2 = ![]() and x3 =
and x3 = ![]() . Let us suppose that Q also has three elements, with the as yet
unknown probabilites labeled as y1, y2
and y3. Let me now suppose
that the collection {f(w|q)} that would
appear in (4.6) makes (4.7) into the following system of equations:
. Let us suppose that Q also has three elements, with the as yet
unknown probabilites labeled as y1, y2
and y3. Let me now suppose
that the collection {f(w|q)} that would
appear in (4.6) makes (4.7) into the following system of equations:
![]() =
= ![]() y1 +
y1 + ![]() y3
y3
![]() =
= ![]() y2 +
y2 + ![]() y3
y3
![]() =
= ![]() y1 +
y1 + ![]() y2
y2
(4.8)
Thus, our task is to solve the linear system with the associated matrix
A
= 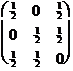 .
.
(4.9)
As it turns out, this matrix is
invertible. In any event, the
Gauss/Jordan reduction method finds that the linear system is solvable with y1
= ![]() , y2 =
, y2 = ![]() , y3 =
, y3 = ![]() .
.
To compare this to the first method, let y*1, y*2, y*3 denote the as yet unknown values of the function P* that appears in the corresponding version of (4.4). In this regard, (4.4) reads here as the equation
y*1 = ![]() a11 x1 +
a11 x1 + ![]() a21 x2 +
a21 x2 + ![]() a31 x3
a31 x3
y*2 = ![]() a12 x1 +
a12 x1 + ![]() a22 x2 +
a22 x2 + ![]() a32 x3
a32 x3
y*3 = ![]() a13 x1 +
a13 x1 + ![]() a23 x2 +
a23 x2 + ![]() a33 x3
a33 x3
(4.10)
where Z1
= a11 + a12 + a13, Z2 = a21
+ a22 + a23 and Z3 = a31+ a32
+ a33. Here, (aij) are the components of the matrix A that
appears in (4.9). Plugging in the values
given above for the aij finds each Zk = 1.
Plugging in the given values for x1, x2 and x3
then finds y*1 = ![]() , y*2 =
, y*2 = ![]() , and y*3
=
, and y*3
= ![]() .
.
·
A best choice for qtr: The question on the table is this: What would be the optimal choice for qtr, the true
values for the parameters in our model?
If we have a probability function for Q, whether Q(q) or P*(q), one
can take qtr to be the mean value as defined using the probability
function: Thus,
qtr º
∑qÎQ Q(q) q or qtr º ∑qÎQ P*(q) q
as the case may be.